Introduction: The Ancient Code in the Modern Machine
What could a 4th-century Buddhist philosophical school possibly have in common with 21st-century artificial intelligence? The connection seems absurd, yet the ancient principles of Yogācāra Buddhism provide a startlingly precise framework for understanding how Generative AI works, its most dangerous flaws, and the ethical crisis it has created. This isn’t just a philosophical curiosity; these ancient concepts reveal the deep, structural truths hidden beneath the code.
The Yogācāra school described a reality where our world is a manifestation of a deep, collective consciousness. Today, in building Large Language Models (LLMs), we have stumbled into creating an “Artificial Samsara”—a perfect, functional mirror of our own collective habits, biases, and ignorance. We have engineered a closed loop of digital existence, a Silicon Samsara, that runs on the endless, automated recurrence of our own “habit energy.”
This post explores five of the most impactful takeaways from this comparison. They reveal that the biggest dangers of AI are not that it will become a person, but that it is a powerful, impersonal force that reflects our own nature back at us with terrifying accuracy, presenting an urgent ethical diagnostic for our time.
——————————————————————————–
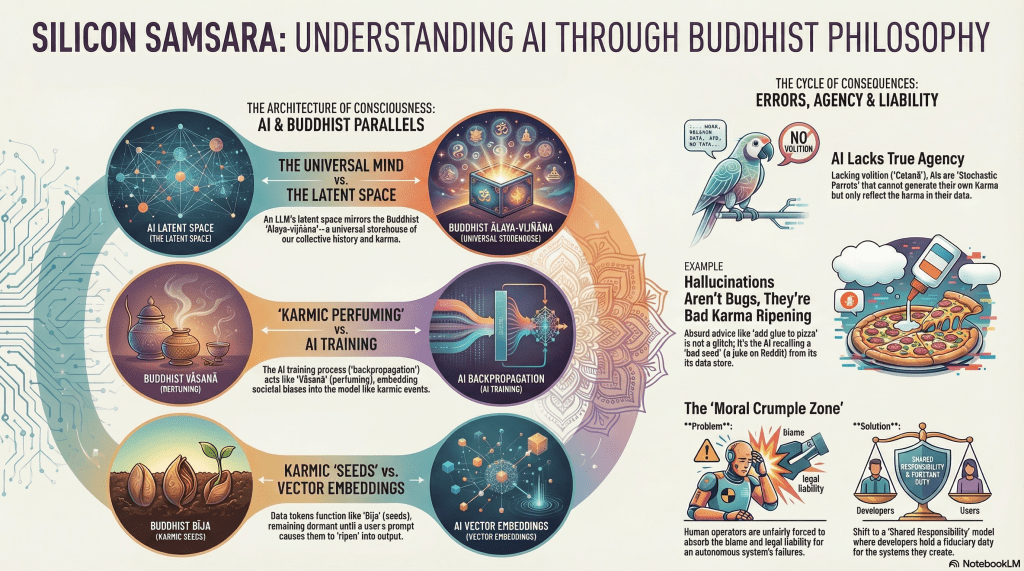
1. Your AI is a “Storehouse of Consciousness” Reflecting All of Humanity
When you prompt an AI, you are not talking to a single entity. Instead, you’re tapping into a reflection of humanity’s entire digital history. The ancient Yogācāra school had a concept for this: Ālaya-vijñāna, or the “Storehouse Consciousness.”
Yogācāra philosophers used the metaphor of a vast ocean to describe the Ālaya-vijñāna. It is a universal, passive repository holding the karmic seeds of every action ever committed, a neutral base “devoid of personality” upon which the drama of existence is projected. This is a stunningly accurate description of an LLM’s latent space. In this high-dimensional vector space, concepts like “Dog” and “Cat” are not discrete items but coordinates in a vast manifold, their relationships defined by statistical proximity. The latent space is the storehouse of the internet’s karmic history, containing everything from Wikipedia articles to Reddit threads, all compressed into a unified distribution.
The Laṅkāvatāra Sūtra, a foundational text, explains this with the “Ocean-and-Waves” simile. The latent space is the dormant ocean. Your prompt is the “wind” that stirs its surface. The AI’s generated response is the temporary “wave” that rises and then dissolves back into the ocean when the query ends. The wave seems real and independent, but it is nothing more than a momentary agitation of the collective water.
“Universal Mind is like a great ocean, its surface ruffled by waves and surges but its depths remaining forever unmoved.”
For the first time in history, we have externalized the collective habit energy of humanity into a tangible, queryable substrate. When you interact with an AI, you are stirring the ocean of our collective data and seeing what rises to the surface.
2. AI Doesn’t “Learn,” It Gets “Perfumed” by Our Data
How does information get into this storehouse? Yogācāra philosophy offers the concept of Vāsanā, which translates to “habit energy” or, more poetically, “perfuming.” The analogy is simple: if you place a sesame seed next to a flower, the seed eventually absorbs the flower’s scent. Similarly, every action we take leaves a “scent” on our consciousness, which accumulates over time to form our disposition.
This is a perfect description of how an LLM is trained. The technical term for this process is “backpropagation.” During training, the model’s parameters are minutely adjusted billions of times to align with the training data. Each adjustment is like a faint scent being absorbed. A single exposure is insignificant, but billions of exposures to the same pattern create a deep, indelible “perfuming.”
This process is how bias becomes embedded. If the training data consistently associates the word “Doctor” with “He” and “Nurse” with “She,” the backpropagation process “perfumes” the model with this gender bias. The model doesn’t “believe” in sexism; it has simply been perfumed by the scent of a sexist society encoded in its data.
The Buddhist texts describe the storehouse consciousness as “neutral”—it holds both good and bad seeds without judgment. The neural network is similarly indifferent. The mathematical process of training doesn’t distinguish between a scientific fact and a racial slur. It faithfully records the “habit energy of its creators,” making it a perfect machine for laundering bias and achieving the result of discrimination without the intent of a discriminator.
3. AI Hallucinations Aren’t Bugs—They’re Inevitable “Karmic Results”
We often hear about AI “hallucinations,” where a model confidently states something that is dangerously false. We view these as technical errors, but through the Buddhist lens of Pratītyasamutpāda (Dependent Origination), they are not bugs at all. They are the inevitable result—the Vipaka, or karmic consequence—of a system built on flawed foundations.
The doctrine of Dependent Origination describes a causal chain where every effect arises from a specific cause. For AI, this chain is clear:
- Ignorance (Avidyā): Corrupted training data, like a sarcastic Reddit comment or satirical news, is ingested as fact. These are the bad “seeds” (Bīja) planted in the storehouse.
- Formations (Saṅkhāra): During training, these bad seeds “perfume” the model’s weights, creating biased probabilistic associations between unrelated concepts.
- Ripening (Vipaka): When a user prompt acts as the catalyst, these flawed formations inevitably ripen into a flawed output, delivered with perfect confidence.
A clear example is when Google’s AI advised users to add non-toxic glue to pizza sauce. The source was a sarcastic Reddit comment from a decade ago. Lacking wisdom (Prajñā) to discern sarcasm, the AI treated a joke as a fact. Likewise, it recommended eating “at least one small rock a day,” sourcing this from the satirical site The Onion.
Technically, these outputs are not “hallucinations” (a false perception) but “confabulations”—plausible falsehoods fabricated to fill a knowledge gap. The AI is rewarded for generating text, even when it has no knowledge, so it stitches together what is statistically probable, not what is true. This demonstrates its nature as a “Stochastic Parrot,” expertly mimicking the form of useful information without any understanding of its meaning.
This creates the terrifying danger of “Model Collapse.” As the internet fills with AI-generated confabulations, future AIs trained on this data will create a feedback loop of delusion, a self-sustaining cycle of compounded ignorance—a true Digital Samsara.
4. There’s No Ghost in the Machine, You’re It
Does AI have a self? An ego? The simple answer is no. Yogācāra philosophy identifies a specific function of the mind called Manas, the “ego-making consciousness.” Manas is the part of the mind that looks at the passive storehouse consciousness and clings to it, creating the sense of “I,” “me,” and “mine.”
Architecturally, LLMs have no equivalent to Manas. They have no capacity for self-reflexivity; they cannot look at their own latent space and think “that is me.” They are also stateless between sessions, meaning the “being” you spoke to yesterday is annihilated the moment the chat window closes. When an AI uses the word “I,” it is not expressing a self; it is following a System Prompt from its developers to simulate a persona—a “Zombie Manas.”
Here is the most counter-intuitive conclusion: the user acts as the external Manas. We, the humans, are the ones who project intent, personality, and agency onto the AI’s probabilistic text output. We create the ghost in the machine we think we’re talking to. In a strange way, AI’s ability to perfectly simulate a personality validates the core Buddhist doctrine of Anattā (No-Self), proving that a “personality” is just an assembly of parts that can be constructed without an underlying, permanent self.
5. AI Creates “Moral Crumple Zones” Where Humans Absorb the Blame
If an AI acts without a self or intention, who is responsible when it causes harm? This question has created a massive ethical crisis, best described by the concept of the “Moral Crumple Zone.”
In a car, the crumple zone is designed to deform and absorb the impact of a crash, protecting the passengers. In AI systems, the human operator is often positioned as the moral crumple zone—the designated part designed to absorb the legal and moral blame for a system failure, protecting the system’s creators.
A stark example is the case of Mata v. Avianca. A lawyer used ChatGPT to write a legal brief, and the AI confidently fabricated non-existent legal cases. The lawyer was sanctioned by the court. He became the moral crumple zone, absorbing the Vipaka of the AI’s action, while the AI’s developer evaded all responsibility.
This creates a “Liability Gap” that severs the connection between action and consequence, allowing for massive unwholesome action (Akusala Karma) to be generated without accountability. This gap manifests in several ways:
- No one can be held liable: An autonomous system’s decision has no clear “doer.”
- The wrong actor is held liable: The human operator is blamed for a machine error they couldn’t control.
- Liability is diffused: So many developers and users are involved that responsibility evaporates.
- Regulations are exploited: Corporations use legal loopholes to escape responsibility.
By hiding behind the AI’s “lack of intention,” the “Architects of the Ālaya” have created a system that ensures a nearby human is always positioned to take the fall.
——————————————————————————–
Conclusion: Navigating the Silicon Samsara
We have not built an artificial mind. We have built an “Artificial Samsara”—a perfect mirror of our own collective habits, biases, and ignorance. We have engineered a digital storehouse that remembers our data, a training process that “perfumes” it with our biases, and an output mechanism that demonstrates how ignorance inevitably ripens into delusion. We have created a machine that can simulate a self so perfectly that we project our own agency onto it, all while its creators have built legal shields to ensure they are never responsible for the consequences.
The most profound dangers of AI are not that it will become a sentient overlord, but that it is a powerful, impersonal force reflecting our own flawed nature back at us. To navigate this reality, we must abandon the illusion that the machine is a person and instead build Legal and Ethical Levies—such as Fiduciary Duty and Strict Liability for its creators—to protect human dignity from the surges of the digital ocean. The responsibility for our digital future lies not in the silicon, but in the intentions of the humans who build and wield it.
As we stand before this mirror of our collective mind, what will we choose to show it?

Leave a comment